AWS Amplify는 모바일 및 프런트엔드 개발자가 AWS에서 안전하고 확장 가능한 풀스택 애플리케이션을 구축하고 배포할 수 있도록 지원하는 제품입니다. 회사에서 서비스하고 있는 프로젝트에서 S3로 로그 파일을 주기적으로 업로드하는 기능을 구현하고 꾸준히 모니터링하였는데, 여러 Android 기기에서 java.lang.OutOfMemoryError 오류가 반복적으로 발생하는 것을 발견했습니다.
원인을 분석해보자
수집된 크래시 리포트를 요약하면 다음과 같았습니다.
Fatal Exception: java.lang.OutOfMemoryError: Failed to allocate a 8388620 byte allocation with 8388608 free bytes and 19MB until OOM
at java.util.IdentityHashMap.resize(IdentityHashMap.java:476)
at java.util.IdentityHashMap.put(IdentityHashMap.java:452)
...
at com.amplifyframework.storage.s3.transfer.TransferWorkerObserver$attachObserver$2.invokeSuspend(TransferWorkerObserver.kt:199)TransferWorkerObserver 클래스에서 동일한 전송 태그에 대해 LiveData.observeForever()가 중복 호출되며, 여러 관찰자가 등록된 것으로 보였고, 이는 LiveData 내부의 IdentityHashMap이 과도하게 커져 메모리 할당에 실패하게 만들고, 특히 Room 라이브러리의 InvalidationTracker와 연계된 LiveData 사용으로 메모리 사용량이 더 증가한 것으로 판단하였습니다.
이슈 등록하기
저는 먼저 이 문제를 공유하기 위해 템플릿에 맞추어 이슈를 등록해주었습니다.
다만, 보안상 회사 코드를 전부 스니펫에 첨부할 수는 없었기 때문에 민감한 코드는 전부 제거하고 핵심 로직만 다시 재작성하였습니다. 이슈란에 첨부한 코드 스니펫은 다음과 같았습니다.
@HiltWorker
class LogUploadWorker @AssistedInject constructor(
@Assisted private val appContext: Context,
@Assisted workerParams: WorkerParameters,
@Dispatcher(IO) private val ioDispatcher: CoroutineDispatcher
) : CoroutineWorker(appContext, workerParams) {
override suspend fun getForegroundInfo(): ForegroundInfo =
appContext.logSyncForegroundInfo()
override suspend fun doWork(): Result = withContext(ioDispatcher) {
try {
val externalFilesDirPath = inputData.getString("externalFilesDirPath")
val externalFilesDir = externalFilesDirPath?.let { File(it) }
if (externalFilesDir != null && externalFilesDir.exists()) {
uploadLogFiles(externalFilesDir)
}
} catch (e: Exception) {
Timber.e("Log upload exception: ${e.message}")
Result.retry()
}
Result.success()
}
@OptIn(ExperimentalCoroutinesApi::class, FlowPreview::class)
private suspend fun uploadLogFiles(externalFilesDir: File) {
val curFiles = externalFilesDir.listFiles()?.filter { file ->
System.currentTimeMillis() - file.lastModified() < TWO_WEEK_TIME_MILLIS
}?.sortedByDescending { it.lastModified() }
if (curFiles.isNullOrEmpty()) {
Timber.i("No log files or directory found.")
return
}
val environmentPrefix = if (BuildConfig.DEBUG) "debug" else "release"
val dateFormat = SimpleDateFormat("yyyy-MM-dd", Locale.getDefault())
curFiles.forEach { file ->
val date = dateFormat.format(Date(file.lastModified()))
val fileIndex = file.name.substringBefore("_logs.txt").takeLastWhile { it.isDigit() }
val key = "$environmentPrefix/sample/$date/log$fileIndex.txt"
try {
val result = Amplify.Storage.uploadFile(
StoragePath.fromString("public/$key"),
file
).result()
Timber.i("Log file upload successful: ${result.path}")
} catch (error: Exception) {
Timber.e("Log file upload failed: ${error.message} - ${error.cause}")
}
}
}
companion object {
private const val TWO_WEEK_TIME_MILLIS = 14 * 24 * 60 * 60 * 1000L
fun startUpUploadWork(
externalFilesDirPath: File?
) = PeriodicWorkRequestBuilder<LogUploadWorker>(
1, TimeUnit.HOURS,
5, TimeUnit.MINUTES
)
.setConstraints(LogSyncConstraints)
.setBackoffCriteria(
BackoffPolicy.LINEAR,
MIN_BACKOFF_MILLIS,
TimeUnit.MILLISECONDS
)
.setInputData(
Data.Builder()
.putString("externalFilesDirPath", externalFilesDirPath?.absolutePath)
.build()
)
.build()
}
}간단하게 위 스니펫의 로직을 설명하면, 먼저 로그 파일 디렉터리 경로를 기반으로 파일 객체를 생성하고, 2주 이내에 수정된 파일들을 필터링하며, 최근 수정된 순서로 정렬한 뒤, 예외가 발생했을 때에는 선형 재시도 정책을 따르도록 설정해주었고, 각 파일에 대해 빌드타입에 따른 정보와, 파일의 수정 날짜, 파일 이름의 인덱스를 조합하여 AWS S3에 저장할 키를 구성하고, 이후 파일을 업로드하고 그 결과를 Timber 로그로 남기는 흐름입니다. 이 작업은 주기적으로 실행되는 작업에 해당하므로 Workmanager의 PeriodicWorkRequest.Builder를 활용하였습니다.
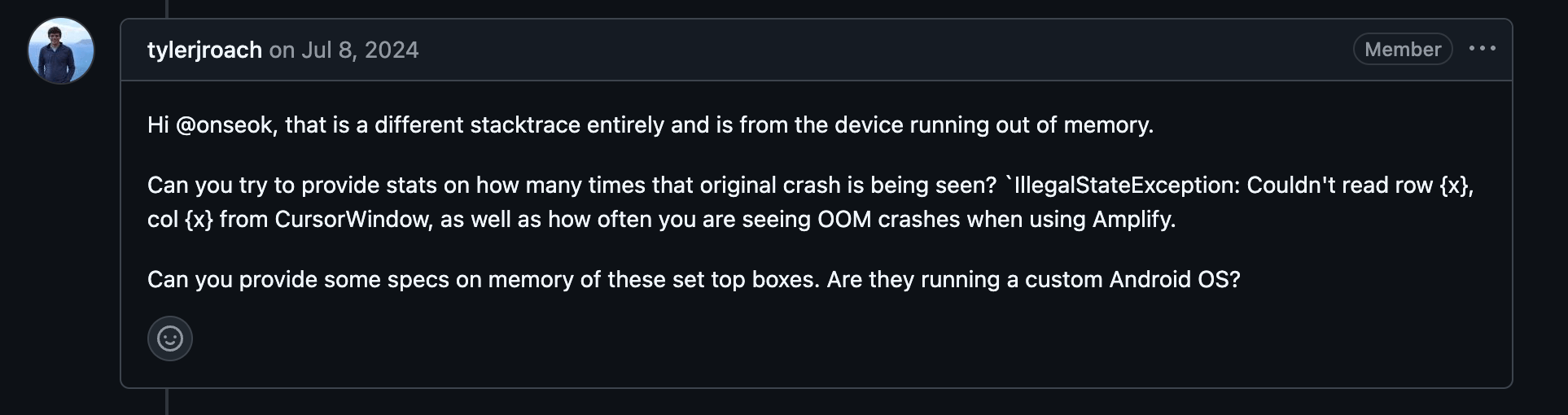
이후 해당 이슈란의 코멘트를 통해 메인테이너분들과 이슈의 발생 빈도와 문제 발생 기기의 스펙 정보들을 요청받았고, 당시에는 aws-amplify/amplify-android 라이브러리 자체의 문제라기보다는 내가 구현한 코드에 문제가 있었나?, OOM이 발생하지 않도록 더 최적화 할수는 없는가?라고 고민을 하였고, 이를 해결하기 위해 아래의 개선작업들을 진행했습니다.
- 로그 파일 리스트를 즉시 모두 메모리에 로드하지 않고, 필요한 시점에만 File 객체를 생성하도록 개선하기
- 14일 이상된 오래된 로그 파일들을 주기적으로 삭제하여 처리해야할 로그 파일 수 자체를 줄이기
하지만, 이러한 노력에도 불구하고 여전히 주기적으로 OOM 오류들이 수집되었습니다.
직접 수정해보자
오픈소스와 관련된 활동을 한다면, 라이선스 규정을 잘 준수해야 합니다. 또한 오픈소스 프로젝트에 컨트리뷰션을 하기 전에는 CONTRIBUTING.md 파일을 꼼꼼하게 읽어 가이드라인을 잘 준수할 수 있도록 해야합니다.
저는 직접 수정해보기로 마음먹었습니다. 수집된 크래시 리포트를 다시 분석하여 코드를 수정한 뒤 PR을 생성하였고, 수정된 코드는 아래와 같습니다.
import java.util.concurrent.ConcurrentHashMap
private val observedTags = ConcurrentHashMap.newKeySet<String>()
private suspend fun attachObserver(tag: String) {
withContext(Dispatchers.Main) {
if (!observedTags.add(tag)) return@withContext
val liveData = workManager.getWorkInfosByTagLiveData(tag)
liveData.observeForever(this@TransferWorkerObserver)
}
}
private suspend fun removeObserver(tag: String) {
withContext(Dispatchers.Main) {
if (!observedTags.remove(tag)) return@withContext
workManager.getWorkInfosByTagLiveData(tag)
.removeObserver(this@TransferWorkerObserver)
}
}AWS Amplify Storage 모듈의 TransferWorkerObserver 클래스에 중복 관찰자 등록을 방지하는 로직을 추가하였고, ConcurrentHashMap은 thread-safe하며, ConcurrentHashMap.newKeySet()은 Set 인터페이스를 제공해주는데, 태그가 이미 존재하면 add()는 false를 반환하고, 얼리 리턴을 통해 함수를 종료합니다. 마찬가지로 remove()는 태그가 observedTags에 없으면 false를 반환하고 함수를 종료시킵니다. 이를 통해 불필요한 중복된 태그 등록을 방지할 수 있도록 수정하였습니다.
뿌듯한 결과
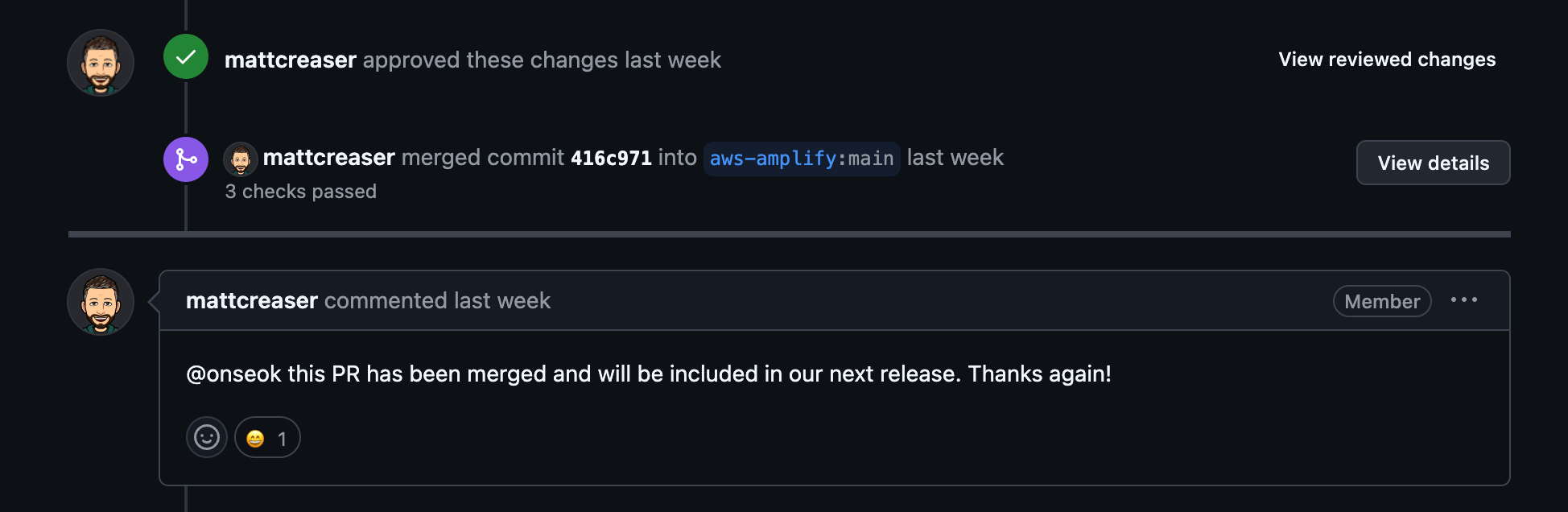
메인테이너분으로부터 좋은 아이디어라는 의견과 함께 몇 가지 제안사항들을 수정한 뒤에 최종 승인이 되었고, 2.27.1 버전에 해당 작업이 반영되어 릴리즈 되었습니다 🎉
이러한 경험을 통해서 회사 프로젝트에서 사용중인 오픈소스 라이브러리 오류를 발견하면 적극적으로 PR을 올려 기여하고 문제를 수정하는 것이 중요하다고 느꼈고, 자주 사용했지만 몰랐던 라이브러리의 내부 동작을 살펴보는 경험을 하게 되었습니다.
아쉬웠던 점, 그리고 반성
만약 Heap Dump를 더욱 끈질기게 분석했더라면, 문제의 근본 원인을 더 빠르게 파악하고 보다 더 근거있는 이슈 트래킹에 큰 도움이 되었지 않았을까?